🧭 Processing large map data
🚉 On Trains: Post #5
Introduction
As part of my master's thesis, I want to compute the optimal train route between cities during a certain period. In my last blogpost, I briefly talked about my frustration setting up OpenTripPlanner, a popular trip planner, and why I decided to look for other alternatives instead. I am planning on releasing a more detailed comparison in a future blogpost.
A trip planner generally takes in two data sources: transit data (when the buses/trains are going), most often in GTFS format (see my previous blogpost about open GTFS data here), and map data. Map data is not always required but gives more accurate results, as two train stations may be close to each other and therefore reachable by foot or bike. Approximations can, of course, always be made by looking at the distance between each station with an average walking/cycling time per km, but this leads to less accurate results and provides fewer insights about what areas can be reached at the destination.
For map data, Open Street Map (OSM) is the de-facto standard. It is a wonderful open source project, which I encourage anyone to support and use.
All Trip planners I looked at used OSM data in .osm.pbf format, which from my understanding is a highly-zipped format of the raw OSM data.
I am working with large-scale data (all of Europe), on consumer hardware. That is probably an unusual use case. Most research centres/organisations seem to have large computing hardware, with GitHub issues discussing whether 1TB of ram is enough for all of Germany.
I therefore had to find multiple ways to reduce the size of the map data to be able to load it all into memory. Even simply iterating through all the elements in the map of Europe takes ~30 min.
This blogpost will briefly discuss the different approaches I took to do so, and how I attempted to optimise my code in not-the-most-optimised language, Python.
Short introduction on the OSM data format
Before starting to work with OSM data, it's important to have a good understand of what the data is about and for who it was built. The history of Open Street Maps is fascinating, outside the scope of this blogpost, and I quite frankly don't feel like I've researched it enough to write about it. What is most important is that the data is meant to represent the state of things as they are, not to fit a specific scope.
What does the data consist of? The pyosmium python package, a tool I will use later, provides a great concise introduction to how OSM data works, which I recommend anyone to read.
There are 3 data types: nodes, ways, and relations. Each object can have tags (attributes), which define whether a node represents a building, a water fountain, or part of a rail track. The naming for tags is decided through consensus through users, and the OpenStreetMap Wiki provides a list of agreed-upon tags.
Nodes are single points, with latitude and longitude, an ID, and tags. Ways are a sequence of points, that can represent a segment of a road, or an area, ... Relations are used to represent more complex areas, such as a transport route (consisting of multiple tracks - ways) or a park.
The general plan
As mentioned before, the scale of my project is the European Union. The amazing website geofabrik provides pbf files of different geographical locations at different periods of time. The latest file for "Europe" is around 30GB. That's a lot, and of course makes my poor little machine crash when attempting to load it in most trip planner software.
How can it be made smaller? The .osm.pbf file contains a lot of data, most of which is not required for the scope of my research, such as the location of public toilets and opening hours of businesses.
Since I am only interested in keeping public-transit related data, I needed to find a list of OSM attributes to keep. Luckily, the documentation for Conveyal's r5, another trip planner, provides a recommended list of attributes to keep.
Using the recommended osmium tool to filter the tags, I was able to reduce the size of the file to less than 8GB! The script took 2h26m to run, but was well worth the wait.
We can do more!
I was currently keeping map data of the most remote places in Europe: on top of a mountain, in places where trains don't even exist... To only keep data in places that really mattered, I decided to build a list of all train stations in my GTFS files, and filter the map to only keep data at a radius of each station.
The osmium bash tool didn't directly allow fur such filtering. As often with these niche projects, a German developer single-handedly maintains a python package called pyosmium for more than 7 years, with complete documentation and examples.
This tool allows iterating through the elements in the file .osm.pbf file, and write them to a new file. The python package, however, runs much slower than the bash equivalent (as expected), and I estimate the equivalent of the filtering command to be at least 4 times slower on my machine.
The popular Scipy python package provides fast tools for comparing coordinates and finding the closest coordinate from a list. This can be done using a KDTree, which provides surprisingly fast results for 2-dimensional data.
Other things I could have done
I later realised that instead of filtering the whole map of Europe, I could have looked at the locations of the train stations to extract a bounding box, and avoid iterating through nodes outside the bounding box.
I also attempted to use threads to filter out the nodes in a batch when comparing the location with a KDTree, but this turned out to be slower, as a new object needed to be created when writing given that only the current OSM object is stored in pyosmium, taking significantly more time.
Testing out the results
I have so far only had time to test my results on this GTFS file from the Aachen AVV company, and a map of all of Germany.
The result below shows all kept OSM objects (blue points), given the train stations (blue markers) at a 1km radius. It works!
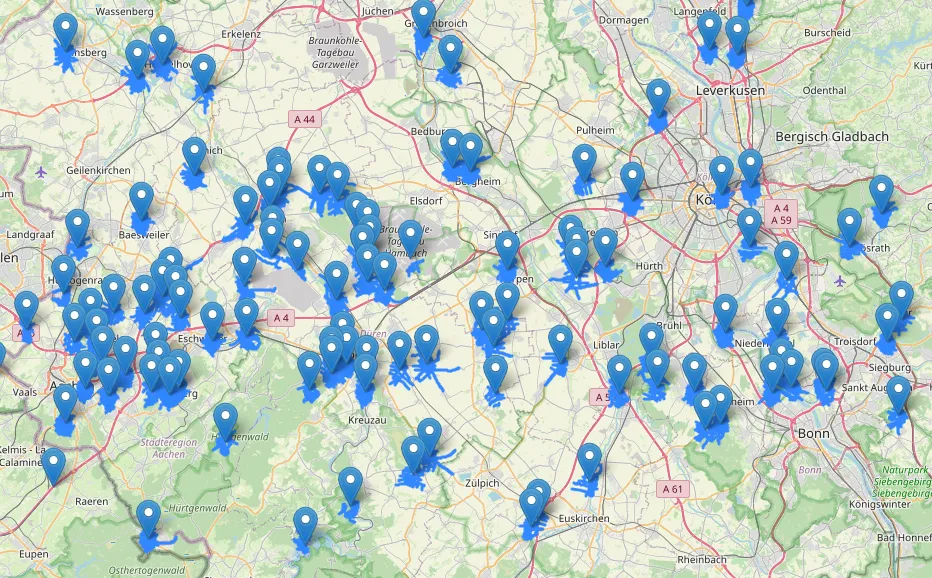
Unfortunately, for large files (like all of Europe), this still seems to make my machine crash. The solution I will attempt in the coming days is subdividing the file into smaller regions and dealing with them individually before combining them.
Closing thoughts
This blogpost was mostly written during a very eventful 18h40 Night Jet ride from Bucharest to Vienna. A future blogpost, outside the on trains series, will probably be dedicated to the incredible past few weeks I've spent in and around Rumania.
As has been the case for many other past blogposts as well, I can't help but feel that the writing was a little more rushed than I would have liked. I would have liked to write about a comparison of different trip planners, but my slower progress required an intermediate post for processing OSM data. I am quite happy about this intermediate blogpost tho, it's nice not to rush things! I will be filtering all of Europe next.
Note: no text in this document has been generated or rewritten by a Large Language Model.